Custom algorithm
Surrogate Gradient Algorithms
During backpropagation of a spiking neural network, the gradient of the spiking activation function \(output\_spike = sign(V>V_th)\) is:
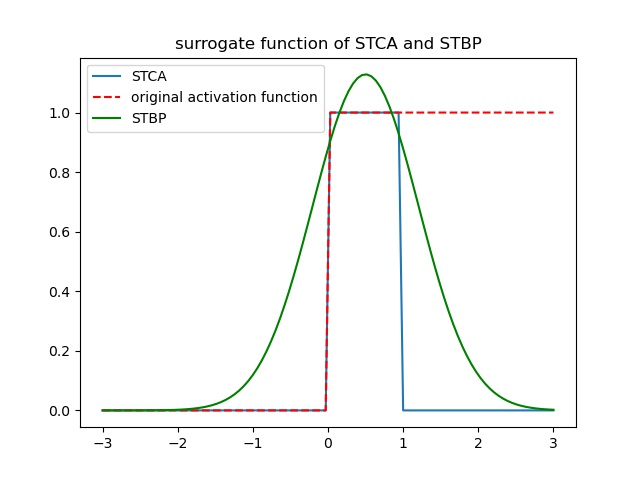
Obviously, directly using the impulse activation function for gradient descent will make the training of the network extremely unstable, so we use the gradient surrogate algorithm to approximate the impulse activation function.The most import part of surrogate gradient algorithms is that use custom gradient function to replace the original backpropagation gradient. Here we use STCA and STBP as examples to show how to use custom gradient formula.
In STCA [1] learning algorithm, the graident function is:
\(h(V)=\frac{1}{\alpha}sign(|V-\theta|<\alpha)\)
In STBP [2] learning algorithm, the graident function is:
\(h_4(V)=\frac{1}{\sqrt{2\pi a_4}} e^{-\frac{(V-V_th)^2)}{2a_4}}\)
The comparison between the gradient surrogate function of the two gradient surrogate algorithms and the original activation function is shown in the figure:
The following code block shows the forward and backpropagation process using the gradient surrogate algorithms.
@staticmethod
def forward(
ctx,
input,
thresh,
alpha
):
ctx.thresh = thresh
ctx.alpha = alpha
ctx.save_for_backward(input)
output = input.gt(thresh).float()
return output
@staticmethod
def backward(
ctx,
grad_output
):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
temp = abs(input - ctx.thresh) < ctx.alpha # According to STCA learning algorithm
# temp = torch.exp(-(input - ctx.thresh) ** 2 / (2 * ctx.alpha)) \ # According to STBP learning algorithm
# / (2 * math.pi * ctx.alpha)
result = grad_input * temp.float()
return result, None, None
Synaptic Plasticity Algorithms
Hebbian Rule shows in the theory about synapse formation between neurons that the firing activity of a pair of neurons before and after a synapse will affect the strength of the synapse between them,
The time difference between pre- and post-synaptic neuron firing determines the direction and magnitude of changes in synaptic weights.
This weight adjustment method based on the time difference between pre- and post-synaptic neuron spike is called spike time-dependent plasticity (STDP), which is an unsupervised learning method
We have constructed two kinds of STDP learning algorithm. The first one is based on the global synaptic plasticity, we call it full_online_STDP [3] ,another one is based on the nearest synaptic plasticity, we call it nearest_online_STDP [4] .
The difference between the two algorithms lies in the update mechanism of the pre- and post-synaptic spike traces.
Here we take the global synaptic plasticity STDP algorithm as an example.
Full Synaptic Plasticity STDP learning algorithm
The weight update formula and weight normalization formula of this algorithm [2] :
Among them, the pre-synaptic and post-synaptic spike traces of the global synaptic plasticity STDP learning algorithm are:
Differently, the STDP learning algorithm based on the plasticity of the nearest neighbors resets the corresponding trace to 1 when there is a spike, and decays at other times. The presynaptic and postsynaptic spike traces are:
At first, get the presynaptic and postsynaptic NeuronGroups from trainable_connection :
preg = conn.pre
postg = conn.post
Then, get parameters ID, such as input spike, output spike and weight name:
pre_name = conn.get_input_name(preg, postg)
post_name = conn.get_group_name(postg, 'O')
weight_name = conn.get_link_name(preg, postg, 'weight')
Add necessary parameters to Backend :
self.variable_to_backend(input_trace_name, backend._variables[pre_name].shape, value=0.0)
self.variable_to_backend(output_trace_name, backend._variables[post_name].shape, value=0.0)
self.variable_to_backend(dw_name, backend._variables[weight_name].shape, value=0.0)
Append calculate formula to Backend :
self.op_to_backend('input_trace_temp', 'var_mult', [input_trace_name, 'trace_decay'])
self.op_to_backend(input_trace_name, 'add', [pre_name, 'input_trace_temp'])
self.op_to_backend('output_trace_temp', 'var_mult', [output_trace_name, 'trace_decay'])
self.op_to_backend(output_trace_name, 'add', [post_name, 'output_trace_temp'])
self.op_to_backend('pre_post_temp', 'mat_mult_pre', [post_name, input_trace_name+'[updated]'])
self.op_to_backend('pre_post', 'var_mult', ['Apost', 'pre_post_temp'])
self.op_to_backend('post_pre_temp', 'mat_mult_pre', [output_trace_name+'[updated]', pre_name])
self.op_to_backend('post_pre', 'var_mult', ['Apre', 'post_pre_temp'])
self.op_to_backend(dw_name, 'minus', ['pre_post', 'post_pre'])
self.op_to_backend(weight_name, self.full_online_stdp_weightupdate,[dw_name, weight_name])
Weight update part:
with torch.no_grad():
weight.add_(dw)
Weight normalization part:
weight[...] = (self.w_norm * torch.div(weight, torch.sum(torch.abs(weight), 1, keepdim=True)))
weight.clamp_(0.0, 1.0)
Reward-Regulated Synaptic Plasticity Algorithm
The reward-regulated synaptic plasticity algorithm can be regarded as a STDP/Anti-STDP learning mechanism for correct or wrong decisions, respectively, that is, the reward or punishment signal generated by the behavioral results of the neural network is used to exert influence on the weight update of neurons. Two RSTDP learning algorithms are implemented on our platform, one is RSTDP learning algorithm based on eligibility trace[#f5]_, and the other is RSTDP learning algorithm based on surrogate gradient [6] . Let’s take the first algorithm as an example.
RSTDP Learning Algorithm Based on Eligibility Trace
The weight update equation of the algorithm:
Among them, the eligibility trace update formula is:
First get the pre-synaptic neuron group and post-synaptic neuron group trained by the learning algorithm from trainable_connection:
preg = conn.pre
postg = conn.post
Then get the backend name of the parameters required by the learning algorithm
such as input pulse, output pulse and connection weight. We refer to the function of getting the name in Connection and define intermediate variable names,
such as pre- and post-synaptic pulse traces and eligibility traces.
.. code-block:: python
pre_name = conn.get_input_name(preg, postg) post_name = conn.get_group_name(postg, ‘O’) weight_name = conn.get_link_name(preg, postg, ‘weight’) p_plus_name = pre_name + ‘_{p_plus}’ p_minus_name = post_name + ‘_{p_minus}’ eligibility_name = weight_name + ‘_{eligibility}’
Then add the parameters needed by the algorithm to the backend
self.variable_to_backend(p_plus_name, pre_shape, value=0.0)
self.variable_to_backend(p_minus_name, backend._variables[post_name].shape, value=0.0)
self.variable_to_backend(eligibility_name, backend._variables[weight_name].shape, value=0.0)
Then add the formula to the backend
self.op_to_backend('p_plus_temp', 'var_mult', ['tau_plus', p_plus_name])
if len(pre_shape_temp) > 2 and len(pre_shape_temp) == 4:
self.op_to_backend('pre_name_temp', 'feature_map_flatten', pre_name)
self.op_to_backend(p_plus_name, 'var_linear', ['A_plus', 'pre_name_temp', 'p_plus_temp'])
else:
self.op_to_backend(p_plus_name, 'var_linear', ['A_plus', pre_name, 'p_plus_temp'])
self.op_to_backend('p_minus_temp', 'var_mult', ['tau_minus', p_minus_name])
self.op_to_backend(p_minus_name, 'var_linear', ['A_minus', post_name, 'p_minus_temp'])
self.op_to_backend('post_permute', 'permute', [post_name, permute_name])
self.op_to_backend('pre_post', 'mat_mult', ['post_permute', p_plus_name + '[updated]'])
self.op_to_backend('p_minus_permute', 'permute', [p_minus_name + '[updated]', permute_name])
if len(pre_shape_temp) > 2 and len(pre_shape_temp) == 4:
self.op_to_backend('post_pre', 'mat_mult', ['p_minus_permute', 'pre_name_temp'])
else:
self.op_to_backend('post_pre', 'mat_mult', ['p_minus_permute', pre_name])
self.op_to_backend(eligibility_name, 'add', ['pre_post', 'post_pre'])
self.op_to_backend(weight_name, self.weight_update, [weight_name, eligibility_name, reward_name])
Weight update code:
with torch.no_grad():
weight.add_(dw)